Pytorch RNN Layer
- [nn.RNN]
- 파라미터
- input_size: 입력 데이터의 features size(개수)
- hidden_size: Layer의 Hidden size
- num_layers: 몇층으로 Layer을 쌓을지 개수
- nonlinearity: 활성함수로 'tanh' (Default), 'relu' 둘 중 하나 지정.
- batch_first: True - (batch, seqence len, ..) False - (sequence len, batch, ..). Default: False
- dropout: Dropout rate 비율
- bidirectional: 양방향 적용 여부. Default: False
RNN Layer의 input / output tensor 의 shape
추론시 Input
- Input_Data, Hidden_state
- Input_data의 shape
- (Sequence_legnth, batch_size, feature_shape)
- pytorch 는 입력으로 batch 보다 sequence length가 먼저 온다.
- batch_first=True 로 설정하면 (batch_size, seq_len, feature_shape) 순이 된다.
- ex) 주가 데이터
- feature: 시가, 종가, 최고가, 최저가
- sequence: 100일치
- batch size: 30
- (100, 30, 4) - Hidden_state의 shape
- 시작(초기) hidden state로 입력하지 않으면 0이 들어간다.
- shape은 아래 hidden state 설명 참조

Output
- (output_data, hidden_state)
- output_data과 hidden state를 tuple로 묶어서 반환한다.
- Output_data:
- 매 time step의 출력결과
- Many to Many일 경우 이것을 출력결과로 사용한다.
- hidden_state
- 마지막 time step의 출력결과
- Many to one의 경우 이것을 출력결과로 사용한다.
Output shape - (Sequence length, batch_size, hidden_size * D)
- D: 2 if bidirectional else 1
- batch_first=True 로 설정하면 (batch_size, seq_len, feature_shape) 순이 된다.
- ex)
- RNN Layer의 hidden size가 256 인 경우. (sequence length: 100, batch size: 30, bidirection=False)
- (100, 30, 256)

Hidden state
- 마지막 time step의 출력결과
- (D * layer수, batch_size, hidden_size)
- D: 2 if bidirectional else 1
- layer수: multi layer일 경우 layer stack 수
input_data 생성
import torch
import torch.nn as nn
input_data = torch.randn((100, 30, 4))
# [sequence, batch, feature]
# (100, 30, 4) # 하나의 데이터포인트가 4개 속성으로 구성된 순서대로 100개씩 묶은 sequential 데이터가 30개(묶음)
처리결과 확인하기
rnn1 = nn.RNN(input_size=4 # 데이터포인트의 feature 개수
,hidden_size=200 # Layer의 노드(유닛) 개수
,num_layers=1 # Multi Layer의 개수 (몇 층을 쌓을 건지.)
)
print("======Input: (100, 30, 4), RNN: hidden_size: 200, num_layesr=1, bidirectional=False(기본)======")
output1, hidden_state1 = rnn1(input_data)
print(f"Output: {output1.shape}, Hidden state: {hidden_state1.shape}")
## output: 모든 time step에 대한 처리결과. [100: sequence 크기, 30: batch, 200:unit 개수]
### 첫번째 배치데이터의 첫번째 sequence 처리결과 -> output1[0,0]
## hidden state: 마지막 time step의 처리결과.
# [1:마지막 time step, 30: batch, 200: unit수]
처리결과 확인하기
- bidirectional=True
rnn2 = nn.RNN(input_size=4 # 데이터포인트의 feature 개수
,hidden_size=200 # Layer의 노드(유닛) 개수
,num_layers=1 # Multi Layer의 개수 (몇 층을 쌓을 건지.)
,bidirectional=True # 양방향
)
print("======Input: (100, 30, 4), RNN: hidden_size: 200, num_layers=1, bidirectional=True(기본)======")
output2, hidden_state2 = rnn2(input_data)
print(f"Output: {output2.shape}, Hidden state: {hidden_state2.shape}")
# output: [100: seq, 30: batch, 400: hidden_size * 2(각 방향별로)]
# hidden_state: [2: 양방향, 30: batch, 200: 유닛수(hidden_size)]
처리결과 확인하기
- num_layers=3 (Multi Layer)
rnn3 = nn.RNN(input_size=4 # 데이터포인트의 feature 개수
,hidden_size=200 # Layer의 노드(유닛) 개수
,num_layers=3 # Multi Layer의 개수 (몇 층을 쌓을 건지.)
)
print("======Input: (100, 30, 4), RNN: hidden_size: 200, num_layers=3, bidirectional=False(기본)======")
output3, hidden_state3 = rnn3(input_data)
print(f"Output: {output3.shape}, Hidden state: {hidden_state3.shape}")
# output: [100: seq, 30: batch, 200: 유닛수(hidden_size)]
# hidden state: [3: layer 수, 30: batch, 200: 유닛수]
## hidden의 경우는 모든 layer의 최종 timestep의 결과를 묶어서 반환
처리결과 확인하기
- bidirectional=True
- num_layers=3 (Multi Layer)
rnn4 = nn.RNN(input_size=4 # 데이터포인트의 feature 개수
,hidden_size=200 # Layer의 노드(유닛) 개수
,num_layers=3 # Multi Layer의 개수 (몇 층을 쌓을 건지.)
,bidirectional=True
)
print("======Input: (100, 30, 4), RNN: hidden_size: 200, num_layers=3, bidirectional=True======")
output4, hidden_state4 = rnn4(input_data)
print(f"Output: {output4.shape}, Hidden state: {hidden_state4.shape}")
# output: [100: seq, 30: batch, 400: unit수 * 2(양방향)]
# hidden: [6: layer수 *양방향(2), 30: 배치, 200: 유닛수]
## hidden[0] -> 첫번째 레이어의 순방향
## hidden[1] -> 첫번째 레이어의 역방향
RNN(Simple RNN)의 문제
- 입력 데이터의 sequence가 길수록 Gradient Vanishing으로 초기 Sequence에 대한 학습이 안되는 문제가 RNN의 고질적인 문제이다.
- RNN은 activation 함수로 tanh()를 사용한다. tanh()의 gradient는 0 ~ 1 사이의 실수가 나온다. 그래서 sequence가 길어지면 초기 time step의 값에 대한 weight가 업데이트가 되지 않게 된다.
- 초기 Sequence에 대해 학습이 안되어서 기억력 소실문제 라고 한다.
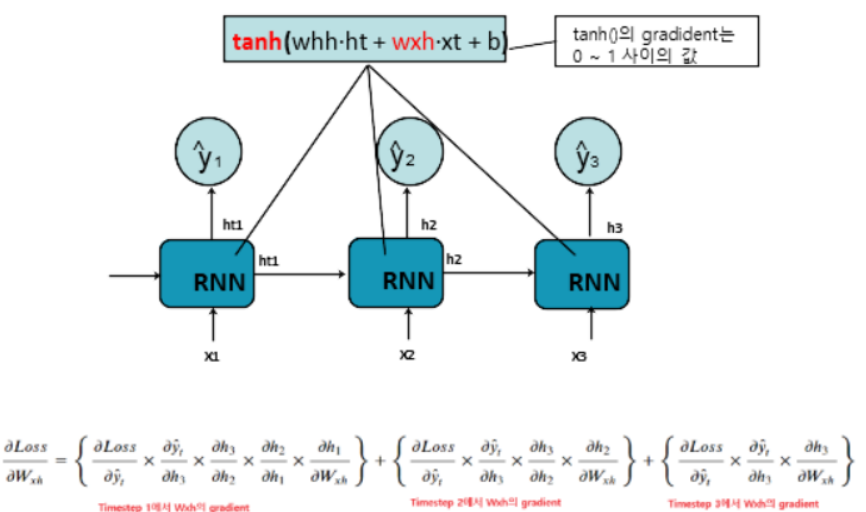
- 이런 Simple RNN의 문제 모델 구조로 해결한 모델이 LSTM이나 GRU 모델이다. Sequence 데이터 처리 모델로 이 둘을 주로 사용한다. 이 글에서는 LSTM을 다룬다.
Pytorch LSTM layer
- [nn.LSTM]
- 파라미터
- input_size: 입력 데이터의 shape
- hidden_size: Layer의 Hidden size
- num_layers: 몇층으로 Layer을 쌓을지 개수
- batch_first: True - (batch, seqence len, ..) False - (sequence len, batch, ..). Default: False
- dropout: Dropout rate 비율
- bidirectional: 양방향 적용 여부. Default: False
추론시 input / output tensor
추론시 Input
- Input_data, (Hidden_state, Cell_state)
- Input_data의 shape
- (sequence_length, batch_size, input_feature_shape) - (Hidden_state, Cell_state)는 생략시 0 입력된다.
- Hidden_state의 shape
- (D * layer수, batch_size, hidden_size)
- D: 2 if bidirectional else 1
- Cell_state의 shape
- (D * layer수, batch_size, hidden_size)
- D: 2 if bidirectional else 1
Output
- Output_data, (Hidden_state, Cell_state)
Output_data의 shape - 모든 timestep의 출력결과를 묶어서 반환
- (sequence length, batch_size, D * hidden_size)
Hidden_state의 shape - 마지막 timestep의 출력결과
- (D * layer수, batch_size, hidden_size)
- D: 2 if bidirectional else 1
Cell_state의 shape - cell state(장기기억) 값
- (D * layer수, batch_size, hidden_size)
- D: 2 if bidirectional else 1
input_data 생성
import torch
import torch.nn as nn
input_data = torch.randn(100, 30, 6) # [seql len, batch수, feature수]
처리결과 확인하기
lstm1 = nn.LSTM(input_size=6 # feature수
,hidden_size=200
,num_layers=1
)
print("======LSTM: hidden_size(unit수)=200, num_layers=1, bidirectional=False======")
output1, (hidden1, cell1) = lstm1(input_data)
# output: 모든 타입 step의 출력 (~~ to many)
# hidden_state: 마지막 step 처리 결과 (~~ to one)
# cell_state: 전체 모든 step에 대한 처리 결과
print(f"output: {output1.shape}, hideen: {hidden1.shape}, cell: {cell1.shape}")
# output: [100: seq개수, 30: batch, 200: hidden크기(유닛수(양방향일 경우 * 2))]
# hidden: [layer수 * 양방향 여부, batch, hidden개수]
# cell: [layer수 * 양방향 여부, batch, hidden개수]
처리결과 확인하기
- bidirectional=True
lstm2 = nn.LSTM(input_size=6 # feature수
,hidden_size=200
,num_layers=1
,bidirectional=True
)
print("======LSTM: hidden_size(unit수)=200, num_layers=1, bidirectional=False======")
output2, (hidden2, cell2) = lstm2(input_data)
# output: 모든 타입 step의 출력 (~~ to many)
# hidden_state: 마지막 step 처리 결과 (~~ to one)
# cell_state: 전체 모든 step에 대한 처리 결과
print(f"output: {output2.shape}, hideen: {hidden2.shape}, cell: {cell2.shape}")
# output: [100: seq개수, 30: batch, 400: hidden크기(유닛수(양방향일 경우 * 2))]
# hidden: [layer수(1) * 양방향 여부(2), batch, hidden개수]
# cell: [layer수(1) * 양방향 여부(2), batch, hidden개수]
'Data_Analysis_Track_33 > Python' 카테고리의 다른 글
| Python_Deeplearning_pytorch_12(DCGan_실습) (1) | 2023.11.03 |
|---|---|
| Python_Deeplearning_pytorch_11(LSTM을 활용한 주가예측) (1) | 2023.11.03 |
| Python_Deeplearning_pytorch_09-2(Transfer Learning과 Fine tuning) (1) | 2023.11.01 |
| Python_Deeplearning_pytorch_09(VGGNet Pretrained 모델을 이용해 이미지 분류) (0) | 2023.10.31 |
| Python_Deeplearning_pytorch_08(Image Augmentation) (0) | 2023.10.30 |


